
XRI Global: LLMs for low-resource languages
At XRI Global, I was part of a team working on a project to assess the depth of divide between high-resource languages and low-resource languages when it comes to AI: translation, speech recognition and generation, conversational models. I worked on all things related to language models: building a solution for aggregating LLMs that support low-resource languages, curating a collection of benchmarks for evaluating LLM performance on low-resource languages and measuring the performance of the models using the Global MMLU dataset.
Our team presented this work at the International Conference on Language Technologies for All in Paris in February 2025. 
Identifying and updating LLMs that support low-resource languages
There are more than 8,500 languages according to Glottolog. On Hugging Face, the largest repository of language models, it is possible to filter results for approximately 4,800 natural languages. There is a problem, though: the results need to be in a format that would allow us to use them for a downstream task, such as visualization or loading the models into a benchmarking pipeline. One additional difficulty is that Hugging Face uses two versions of ISO language codes, ISO 639-1 and ISO 639-3, which means that for some languages, a user would get a different result based on just luck - the two versions look exactly the same on the website interface. We needed information on all models claiming to support a given low-resource language, and we needed a solution that would allow for easy updating as new models were added to Hugging Face. This meant building a custom API interface.
Many courses in the Human Language Technology program highlight the importance of reading and following documentation. Thanks to working on a team project for a Data Mining course, I had a hands-on experience with getting data from an API.
Our solution would have to meet a few important requirements:
- Filtering certain models out: Certain language models have limited conversational abilities, so our team needed a way to filter these out using a simple keyword, where “BLOOM” would filter out any BLOOM-based models in our final results.
- Append and overwrite modes: Our program would have to be able to append to an existing file, effectively updating an existing database of models, or write a new file, for example for a different subset of languages or for a single language.
- Sort by language and by model: Our team needed two types of output. One where the model would be the first column, making it easy to see how many models there are, what languages they support and to compare models among themselves. The other output would have to be sorted by language, listing all available models for each language, enabling us to compare languages in terms of number/types of available language models.
I used huggingface_hub library to interact with Hugging Face API and pandas to manipulate data and export it as a .csv file. The program met all the requirements and is capable of fetching 500+ models in less than 5 minutes!
Full code for my solution with comments can be found in our GitHub repository in llm_benchmarks/hugging_face_scrape
A scoring system for assessing the severity of digital divide
Within our team at XRI Global we developed a scoring system to assess how far ahead or behind a given language is in terms of access to such technologies as translation, ASR, TTS, large language models. At the center of our scoring system were BLEU scores and ChRF scores (both machine translation metrics), WER numbers (a speech-to-text metric) and whether text-to-speech models are available for that language. Our scoring system has a maximum score of 100 and a minimum score of 0. The lower the score, the more affected a given language is by the digital divide. That’s what our scoring system looks like:
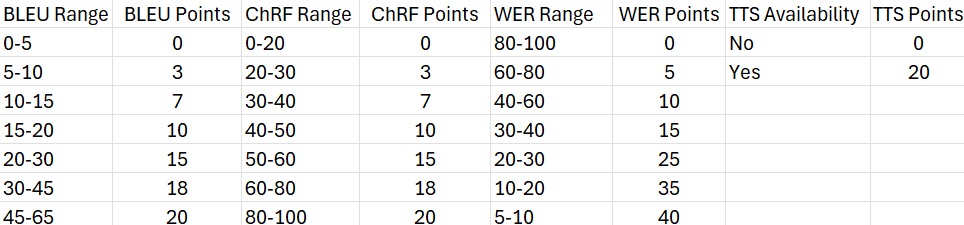
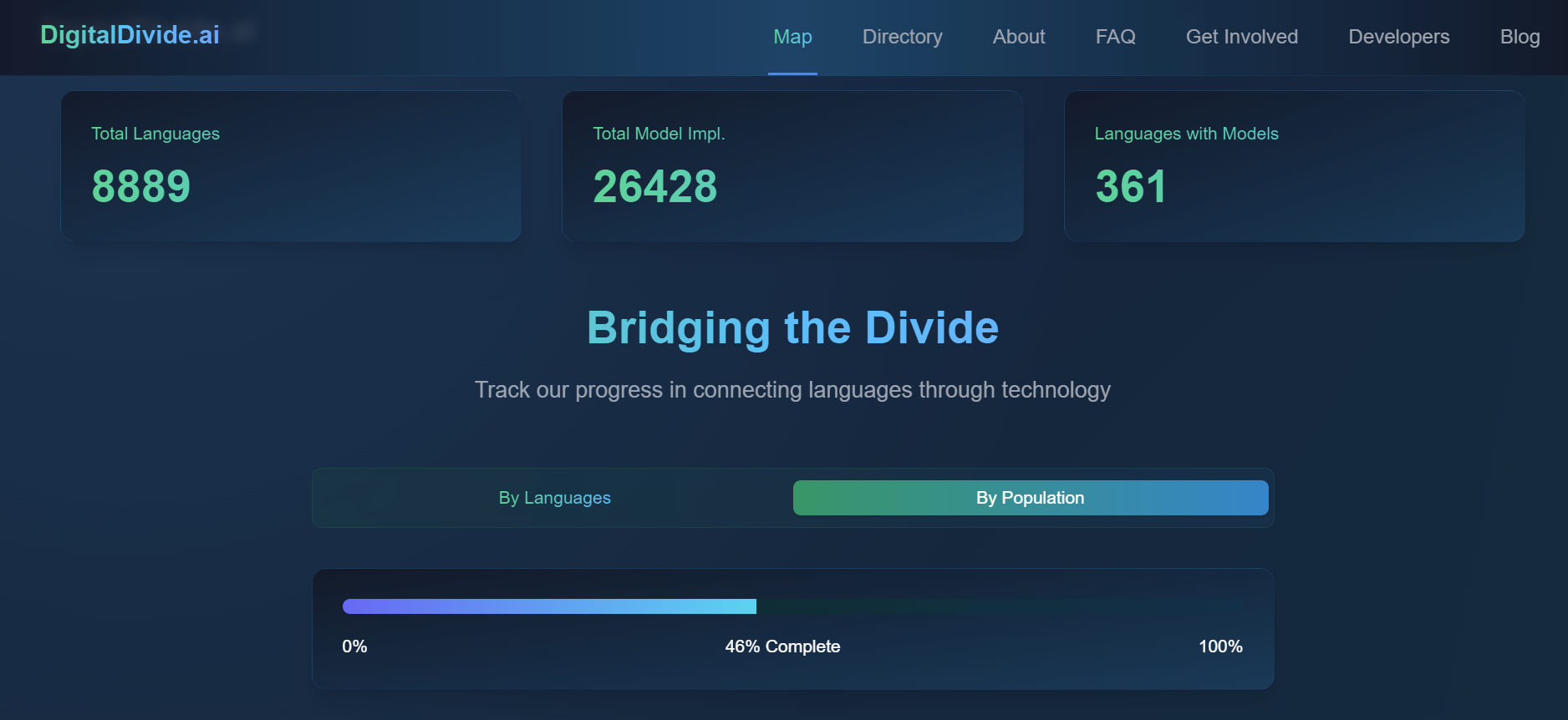
The main difficulty we encountered while using this scoring system was access to information. Publications on some languages are hard to search, and once found, we had to make sure the comparison was a fair one. For example, answering the question of whether a given language has a TTS model available or not will always be tricky, since there is no way to find definitive proof of its absence. I ended up finding all the figures for over 100+ low-resource languages we were working with at the time, and the section of the Applied NLP course dedicated to research made it so much easier to browse academic publications, extract and compare information. Getting the final scores was a matter of a very simple script with a couple dozen if statements. My work was used to build a digital divide progress bar currently displayed on our project website.
Curating a collection of LLM benchmarks for low-resource languages
The majority of my time at XRI Global was spent benchmarking Large Language Models. After examining the thousands of models on Hugging Face, we realized that most of them do not give any performance figures while claiming to support a given low-resource language. One big and obvious problem is the lack of well-crafted datasets in many low-resource languages. And there is unfortunately no way to benchmark reasoning abilities of an LLM without data in that language to benchmark it on. We couldn’t make that data without any proficiency in any given low-resource language. And even if we could, there was still a problem of cross-language comparison between different models. For example, to determine how well model N performs in Amharic compared to how well it performs in English, we would need two versions of the same dataset, rather than just any dataset in a low-resource language.
To begin to solve this problem, I made the largest (to my knowledge) collection of multilingual LLM benchmarks (18 in total). I patiently gathered these benchmarks by reading papers on LLM advances in low-resource languages.
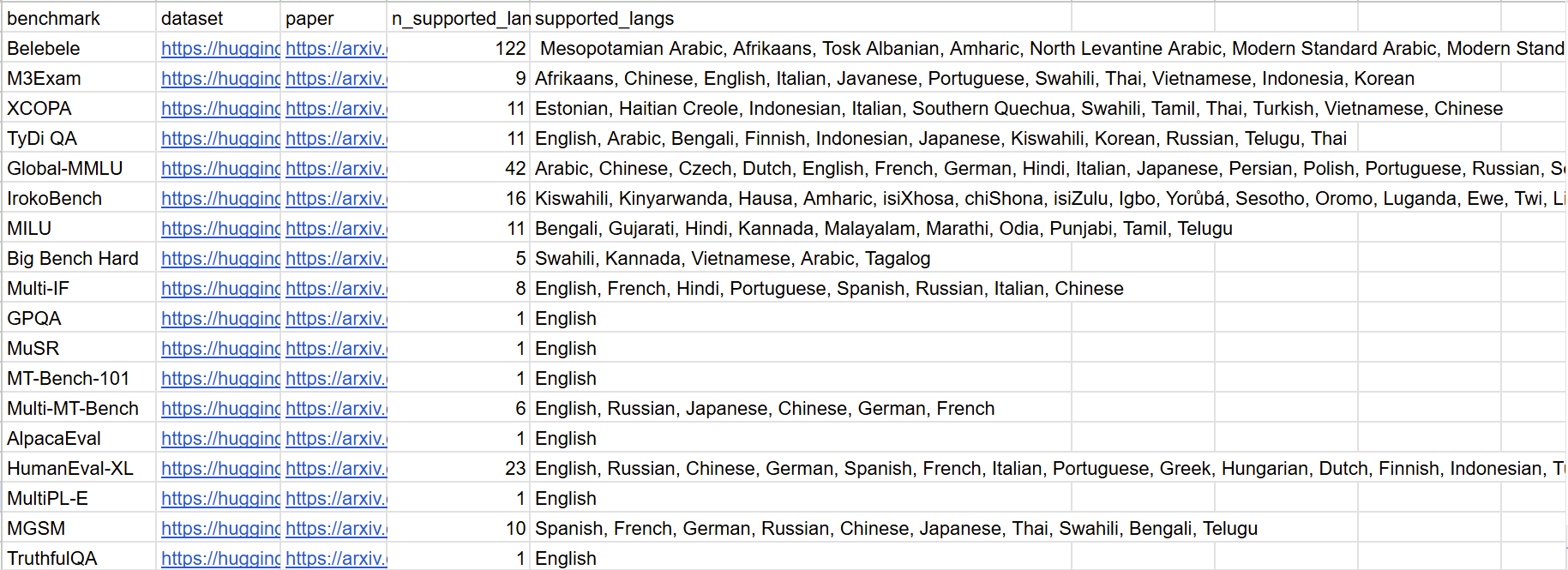
While reading these papers, I also made notes on how often I would see a certain benchmark being mentioned. I noticed that there are various versions of MMLU, such as Global MMLU that supports 42 languages. In addition to being a really popular benchmark for measuring LLM performance in English, there are various translations in multiple low-resource languages. It seemed that MMLU would be a very good candidate for a unifying LLM benchmark, with a wide following and a large number of translations. My conclusions were confirmed by more experienced colleagues at XRI Global, and we decided to start benchmarking models using the Global MMLU dataset.
Benchmarking the performance of LLMs using the Global MMLU dataset
While at XRI Global, I built a pipeline to launch and run a Large Language Model from Hugging Face on a cloud compute platform using Docker. I also managed to benchmark 50 LLMs for 5 different low-resource languages using the Global MMLU dataset.
For all benchmarking sessions, I used a GPU cloud provider RunPod. It is built with AI models in mind, and every instance comes pre-configured with nearly all necessary libraries and software.
It took a few tries to figure out a good way to run and interact with an LLM locally. The combination of Docker and vLLM proved to be almost trouble-free. After our cloud instance would get ready, we could launch a local LLM like so1:

Once our model loads and starts running, we can interact with it using just a few lines of code. But first we need to load the Global MMLU dataset and set important parameters such as language, number of rows to use, format.
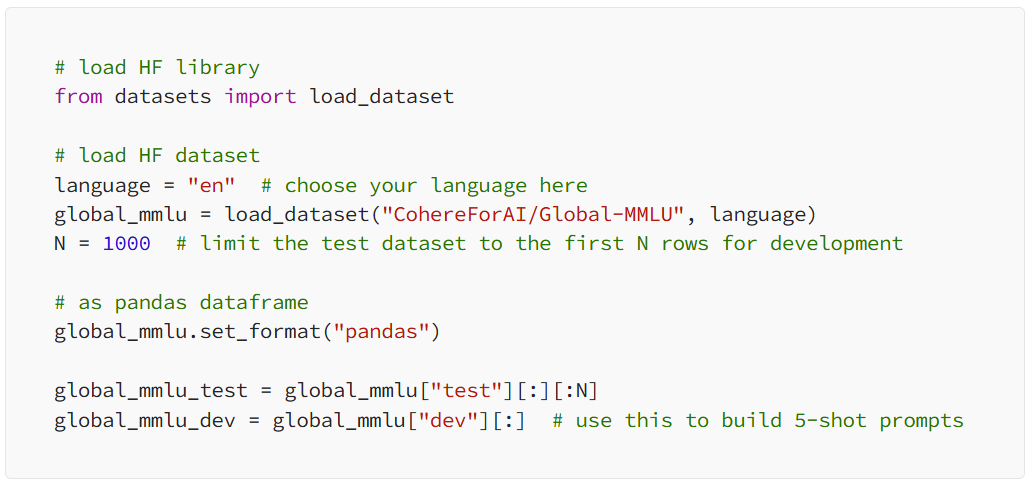
After that it’s just a question of building a prompt, repeatedly querying the LLM for the answer and comparing that answer to the gold labels.

As I mentioned above, during my time at XRI Global, I have run 50+ benchmarks for 5 different low-resource languages. These are the Global MMLU scores that I got as a result. 
For reference, below are the MMLU scores for English and a few other high-resource languages (as of April 2025):
| Language | Model | MMLU Score |
|---|---|---|
| English | GPT-o1 | 0.893 |
| Spanish | Claude-3.5-Sonnet | 0.828 |
| French | Claude-3.5-Sonnet | 0.823 |
| German | Claude-3.5-Sonnet | 0.817 |
| Chinese | AIDC/Macro-72B-Chat | 0.801 |
The method for benchmarking LLMs described here is an implementation of the system outlined in Dr. Leon Eversberg’s publication on the topic. All credit belongs to Dr. Leon Eversberg. ↩