
A light ReAct agent based on GPT-4o-mini
For this course project, I conducted 50 episodes of testing for each test case, and the results demonstrate that the two-step ReAct agent achieves the highest performance, though scoring approximately 17% lower than similar agents using the full GPT-4 model. This suggests that lightweight models, when combined with appropriate prompting strategies, can offer a viable cost-efficient alternative in scenarios where moderate performance trade-offs are acceptable.
Github repository for project code
Introduction
Big LLMs are expensive to run, and the costs add up fast when it is necessary to maintain an extended context. Lighter models with fewer parameters are cheaper, but this usually comes at the cost of performance.
This work explores how well an agent based on one of the lighter LLMs (GPT-4o-mini) can use its reasoning abilities in a simple environment designed to test basic common sense. We will run four sets of simulations in this environment: one where the agent acts randomly, another where the agent uses basic prompting where only action selection is allowed, and two more where agents are given an opportunity to generate reasoning traces before acting, thus emulating reasoning.
This approach, called ReAct, is described in much more detail by Yao et al. (2023)1. Of the two ReAct simulations, one will compact the thinking and acting into one step, and the other will use different steps for thinking and acting.
The TextWorldExpress Commonsense environment
TextWorld (Côté et al., 2019) is a collection of text-based environments that test basic reasoning skills. It can be used as a benchmark for different kinds of agents. This is a good tool for the purposes of this work, since it provides a robust way to measure the ability for basic commonsense reasoning in our agents based on a light GPT-4o mini model. It is a relatively popular benchmark with a good amount of published data, which makes comparing performance across agents easier.
TextWorldExpress (Jansen and Côté, 2022) is a simulator that incorporates 3 environments, including the TextWorld Commonsense used in this work. It is fully compatible with the original TextWorld framework, but it uses more modern tooling that increases the simulation speeds dramatically.
All simulations are run using hard difficulty settings as outlined in the original paper by Murugesan et al. (2020). When loading the environment, a string containing the parameters will be passed to gameParams argument. According to Murugesan et al. (2020), the hard difficulty level should include 1-2 locations and 5-7 objects to find and place. Following the pre-established simulation parameters allows us to compare the results to those in other published works, and this makes the experiment easier to reproduce.
At each step, the environment generates an observation, a list of valid actions, the score, and the episode completeness status. To make the next step, an agent must react with one of the valid actions, and this goes on until the episode is successfully completed or the maximum number of steps is reached. In the case of this work, the number of steps is set at 50, which is consistent with other published works.
Agents
We develop and test two simple agents and two more complex agents. One of the simple agents is a random agent, and the other uses a basic prompt to make GPT-4o-mini select an action.
Of the two more complex agents, one conducts the reasoning and decision making within one step, i.e. the LLM must do the “thinking” and select one of the actions in its next response. The other agent is allowed one extra step where the LLM returns its “thoughts” first, and only then is asked to select an action based on these thoughts in a new prompt.
All LLM-based agents have access to the full context of the last five interactions, including both the user queries and LLM responses (including the intermediary step for the two-step agent). The system prompt containing a very brief outline of the game, as well as the task for the current episode, is also present in every LLM query.
- Random agent: Random agent takes an action at random out of the list of available actions at each step of the episode. Within this work, the random agent is a way to compare how much better our other agents do compared to pure luck.
- Basic agent: All this agent does is to prompt the model with information containing the episode task and the list of valid actions. The LLM is instructed to respond with only the action; it is explicitly instructed to not generate any other text.
One-step ReAct agent: To implement this agent, the LLM is asked to consider the situation, including the results of its previous actions, and select the next move out of a list of valid moves provided by the environment. This approach is depicted in image below (left). The agent does the reasoning and action selection in one step.
- Two-step ReAct agent: This agent also considers its current situation, but instead of performing action selection within the next response, it is asked to think, generating what Yao et al. (2023) call reasoning traces. This process is also depicted in image below (right). After generating the reasoning traces, the model is prompted to select the action based on the reasoning traces generated in the previous interaction.
This is prompt structure for the 1-step ReAct approach vs. 2-step ReAct approach: 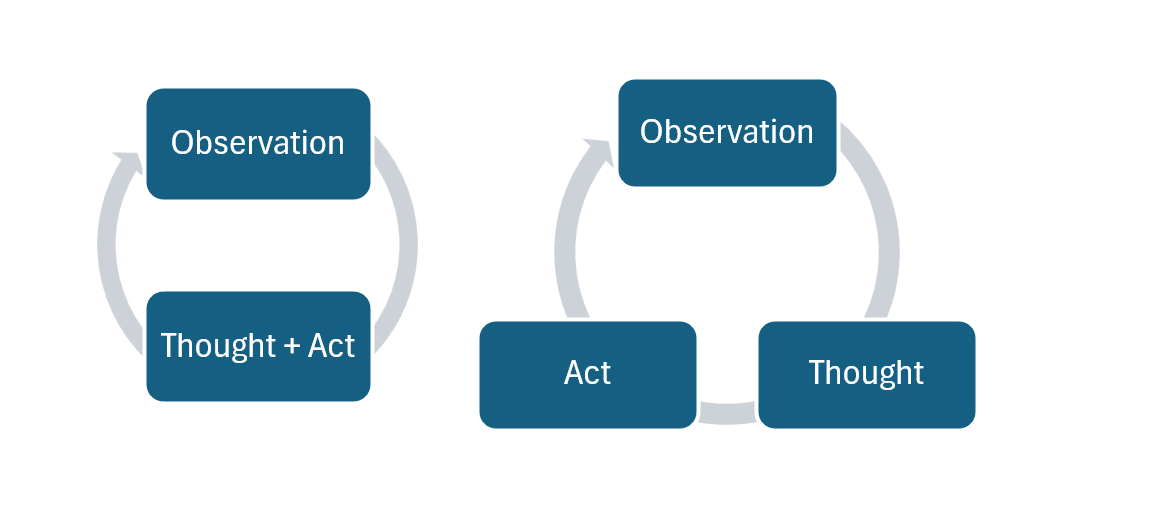
Results and conclusions
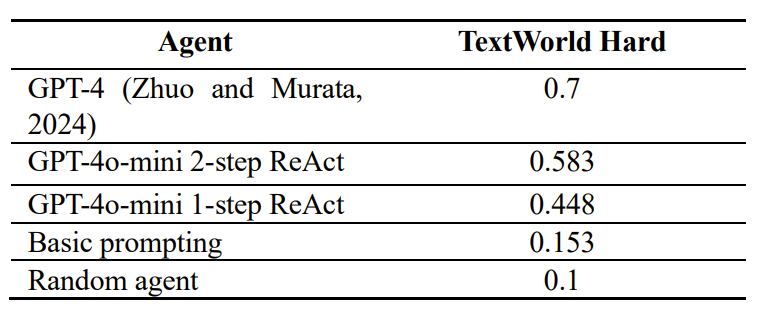
For each of the tested agents, we ran 50 episodes of the TextWorldExpress Commonsense environment. For each of the episodes, an agent was limited to taking up to 50 steps. We also used normalized scores, which appears to be a common practice in other published works on this topic. The results are summarized in Table 1. The numbers in the table are averages of the scores achieved over the 50 runs conducted for each agent.
As seen in Table 1, the random agent predictably gets a low normalized score. Basic prompting gives a better result, but it is still only slightly above 15% of the maximum score that is potentially achievable within the environment. Finally, the two ReAct agents score much higher than simple agents, and two steps yield a noticeable better average score than 1 step, especially considering that breaking the ReAct process into two steps does not lead to a significant increase in tokens spent. We can compare two independent samples using a T-test. For our calculations, we used the ttest_ind_from_stats function from the SciPy package. The results suggest that the performance difference between 1-step and 2-step ReAct agents are statistically significant (raw test score for all tested agents can be found in the repository).
| Agent 1 | Agent 2 | p-value |
|---|---|---|
| GPT-4o-mini 2-step | GPT-4o-mini 1-step | 0.0229 |
| GPT-4o-mini 2-step | Basic agent | <0.0001 |
| GPT-4o-mini 1-step | Basic agent | <0.0001 |
The 2-step ReAct agent based on GPT-4o-mini achieves a score that is approximately 17% lower than a score achieved by a similar agent based on GPT-4 (Zhuo and Murata, 2024). Considering that the GPT-4o-mini is substantially cheaper, there may be situations where a 17% drop in reasoning abilities would be acceptable in exchange for very significant savings.
Prompts
Our prompts are controlled by a simple functions to make sure we provide the right amount of context to the model. The functions always maintain a system message, as well as the last n user/system interactions. In our experiments n was equal to 10.
Basic prompt
def basic_prompt(model, task, obs, valid_actions):
global messages
if not len(messages):
messages.append({"role": "system", "content": f'You are in the middle of a game that checks common sense. \
Your objective in this game is the following: {task}'})
messages.append({"role": "user", "content": f'{obs} Now, given your objective, think how you could achieve it and \
what steps you could take. Remember: there may be multiple locations, \
and you want to avoid repeating things again and again. Now, taking into account \
your thoughts, choose one most reasonable action out of these: {valid_actions}. \
The action has to be in the list and you must respond with the action only, using the same spelling.'})
messages.append({"role": "assistant", "content": f'{ask_openai(model, messages)}'})
messages = [messages[0]] + messages[1:][-11:]
return messages[-1]["content"].replace("'", "")
1-step ReAct prompt
def react_1(model, task, obs, valid_actions):
global messages
if not len(messages):
messages.append({"role": "system", "content": f'You are in the middle of a game that checks common sense. \
Your objective in this game is the following: {task}'})
messages.append({"role": "user", "content": f'{obs} Now, given your objective, think how you could achieve it and \
what steps you could take. Be concise when reasoning, and after generating\
your thoughts, choose one most reasonable action out of these: {valid_actions}. \
The action has to be in the list and you must place the action with # on each side after your thoughts.'})
messages.append({"role": "assistant", "content": f'{ask_openai(model, messages)}'})
messages = [messages[0]] + messages[1:][-11:]
return messages[-1]["content"].replace("'", "").split('#')[1]
2-step ReAct prompt
def react_2(model, task, obs, valid_actions):
global messages
if not len(messages):
messages.append({"role": "system", "content": f'You are in the middle of a game that checks common sense. \
Your objective in this game is the following: {task}'})
messages.append({"role": "user", "content": f'{obs} Now, given your objective, think how you could achieve it and \
what steps you could take. Do not take any action yet, just think. Be concise.'})
messages.append({"role": "assistant", "content": f'{ask_openai(model, messages)}'})
messages.append({"role": "user", "content": f'Remember: there may be multiple locations, \
and if you see that you are going in circles, do not do the same thing again. Now, taking into account \
your previous thoughts, choose one most reasonable action out of these: {valid_actions}. \
The action has to be in the list and you must respond with the action only, using the same spelling.'})
messages.append({"role": "assistant", "content": f'{ask_openai(model, messages)}'})
messages = [messages[0]] + messages[1:][-21:]
return messages[-1]["content"].replace("'", "")
References:
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS.
Marc-Alexandre Côté, Ákos Kádár, Xingdi Yuan, Ben Kybartas, Tavian Barnes, Emery Fine, James Moore, Ruo Yu Tao, Matthew Hausknecht, Layla El Asri, Mahmoud Adada, Wendy Tay, and Adam Trischler. 2019. TextWorld: A Learning Environment for Text-based Games.
Peter A Jansen and Marc-Alexandre Côté. 2022. TextWorldExpress: Simulating Text Games at One Million Steps Per Second.
Keerthiram Murugesan, Mattia Atzeni, Pavan Kapanipathi, Pushkar Shukla, Sadhana Kumaravel, Gerald Tesauro, Kartik Talamadupula, Mrinmaya Sachan, and Murray Campbell. 2020. Text-based RL Agents with Commonsense Knowledge: New Challenges, Environments and Baselines.
Binggang Zhuo and Masaki Murata. 2024. Utilizing GPT-4 to Solve TextWorld Commonsense Games Efficiently. In Proceedings of the 10th Workshop on Games and Natural Language Processing @ LREC182 COLING 2024, pages 76–84, Torino, Italia. ELRA and ICCL.